Run this tutorial
Click here to run this tutorial on mybinder.org:Tutorial: Building a Reduced Basis¶
In this tutorial we will learn more about VectorArrays and how to
construct a reduced basis using pyMOR.
A reduced basis spans a low dimensional subspace of a Model’s
solution_space, in which the
solutions of the Model
can be well approximated for all parameter values. In this context,
time is treated as an additional parameter. So for time-dependent problems,
the reduced space (the span of the reduced basis) should approximate the
solution for all parameter values and time instances.
An upper bound for the possible quality of a reduced space is given by the so-called Kolmogorov \(N\)-width \(d_N(\mathcal{M})\) of the solution manifold
given as
In these definitions, \(V\) denotes the
solution_space, \(\mathcal{P} \subset \mathbb{R}^p\)
denotes the set of all parameter values we are interested in, and
\(u(\mu)\) denotes the solution
of the Model for the given parameter values \(\mu\).
In pyMOR the set \(\mathcal{P}\) is called the ParameterSpace.
How to read this formula? For each candidate reduced space \(V_N\) we look at all possible \(x \in \mathcal{M}\) and compute the best-approximation error in \(V_N\) (the second infimum). The supremum over the infimum is thus the worst-case best-approximation error over all solutions \(x = u(\mu)\) of interest. Now we take the infimum of the worst-case best-approximation errors over all possible reduced spaces of dimension at most \(N\), and this is \(d_N(\mathcal{M})\).
So whatever reduced space of dimension \(N\) we pick, we will always find a \(\mu\) for which the best-approximation error in our space is at least \(d_N(\mathcal{M})\). Reduced basis methods aim at constructing spaces \(V_N\) for which the worst-case best-approximation error is as close to \(d_N(\mathcal{M})\) as possible.
However, we will only find a good \(V_N\) of small dimension \(N\) if the values \(d_N(\mathcal{M})\) decrease quickly for growing \(N\). It can be shown that this is the case as soon as \(u(\mu)\) analytically depends on \(\mu\), which is true for many problems of interest. More precisely, it can be shown [BCD+11], [RD13] that there are constants \(C, c > 0\) such that
In this tutorial we will construct reduced spaces \(V_N\) for a concrete problem with pyMOR and study their error decay.
Model setup¶
First we need to define a Model and a ParameterSpace for which we want
to build a reduced basis. We choose here the standard
thermal block benchmark
problem shipped with pyMOR (see Getting started). However, any pyMOR
Model can be used, except for Section Weak Greedy Algorithm where
some more assumptions have to be made on the Model.
First we import everything we need:
import numpy as np
from pymor.basic import *
Then we build a 3-by-2 thermalblock problem that we discretize using pyMOR’s
builtin discretizers (see
Tutorial: Using pyMOR’s discretization toolkit for an introduction to pyMOR’s discretization toolkit).
problem = thermal_block_problem((3,2))
fom, _ = discretize_stationary_cg(problem, diameter=1/100)
Next, we need to define a ParameterSpace of parameter values for which
the solutions of the full-order model fom should be approximated by the reduced basis.
We do this by calling the space method
of the |parameters| of fom:
parameter_space = fom.parameters.space(0.0001, 1.)
Here, 0.0001 and 1. are the common lower and upper bounds for the
individual components of all |parameters| of fom. In our case fom
expects a single parameter 'diffusion' of 9 values:
fom.parameters
Parameters({diffusion: 6})
If fom were to depend on multiple |parameters|, we could also call the
space method with a dictionary
of lower and upper bounds per parameter.
The main use of ParameterSpaces in pyMOR is that they allow to easily sample
parameter values from their domain using the methods
sample_uniformly and
sample_randomly.
Computing the snapshot data¶
Reduced basis methods are snapshot-based, which means that they build
the reduced space as a linear subspace of the linear span of solutions
of the fom for certain parameter values. The easiest
approach is to just pick these values randomly, what we will do in the
following. First we define a training set of 25 parameters:
training_set = parameter_space.sample_randomly(25)
print(training_set)
[Mu({'diffusion': array([0.77397865, 0.43893455, 0.85861206, 0.69739829, 0.09426793,
0.97562479])}), Mu({'diffusion': array([0.76116359, 0.7860857 , 0.12820082, 0.4504409 , 0.37086094,
0.92677231])}), Mu({'diffusion': array([0.64390073, 0.82277934, 0.44346986, 0.227316 , 0.55462933,
0.06391087])}), Mu({'diffusion': array([0.82764841, 0.63170123, 0.75811193, 0.35459052, 0.97070095,
0.89313181])}), Mu({'diffusion': array([0.77840566, 0.19471924, 0.46677433, 0.04389939, 0.15437406,
0.68308065])}), Mu({'diffusion': array([0.74478768, 0.96751298, 0.32589278, 0.37052266, 0.46960886,
0.18955241])}), Mu({'diffusion': array([0.13000851, 0.47575736, 0.22698666, 0.66984701, 0.4372082 ,
0.83269493])}), Mu({'diffusion': array([0.70029508, 0.3124354 , 0.83227658, 0.80478388, 0.38753963,
0.28839927])}), Mu({'diffusion': array([0.68252725, 0.13983851, 0.19998821, 0.00746153, 0.78694569,
0.66488437])}), Mu({'diffusion': array([0.70519486, 0.78075096, 0.45896988, 0.56878432, 0.13988302,
0.11461862])}), Mu({'diffusion': array([0.66843612, 0.4711491 , 0.56527958, 0.76502236, 0.63475485,
0.55362404])}), Mu({'diffusion': array([0.55925124, 0.3040197 , 0.03091475, 0.43677372, 0.21466321,
0.40858779])}), Mu({'diffusion': array([0.85341773, 0.23401609, 0.05839691, 0.28145575, 0.2936644 ,
0.66195032])}), Mu({'diffusion': array([0.55707645, 0.78391982, 0.66434711, 0.40644622, 0.81403898,
0.16705622])}), Mu({'diffusion': array([0.0228098 , 0.09013886, 0.72238711, 0.46193104, 0.16135565,
0.50109467])}), Mu({'diffusion': array([0.15239687, 0.69635074, 0.44621166, 0.38108312, 0.30158194,
0.63031956])}), Mu({'diffusion': array([0.36187643, 0.08774115, 0.1180941 , 0.96190147, 0.90858983,
0.69973716])}), Mu({'diffusion': array([0.26594337, 0.96917946, 0.77877303, 0.7169185 , 0.44941657,
0.27231434])}), Mu({'diffusion': array([0.09648132, 0.90261214, 0.45583071, 0.20244313, 0.30602603,
0.57926165])}), Mu({'diffusion': array([0.17685511, 0.85662862, 0.75854368, 0.71949101, 0.43214983,
0.62734611])}), Mu({'diffusion': array([0.58413956, 0.64988162, 0.08453588, 0.41586582, 0.04171001,
0.49404142])}), Mu({'diffusion': array([0.32992823, 0.14460974, 0.10349263, 0.58768581, 0.17067591,
0.92512761])}), Mu({'diffusion': array([0.58110303, 0.34693512, 0.5909564 , 0.02290159, 0.95856336,
0.48235521])}), Mu({'diffusion': array([0.78275695, 0.08282173, 0.48670967, 0.49075792, 0.93783267,
0.57177088])}), Mu({'diffusion': array([0.47354205, 0.26704897, 0.33163584, 0.52072034, 0.43896757,
0.02170992])})]
Then we solve the full-order model
for all parameter values in the training set and accumulate all
solution vectors in a single VectorArray using its
append method. But first
we need to create an empty VectorArray to which the solutions can
be appended. New VectorArrays in pyMOR are always created by a
corresponding VectorSpace. Empty arrays are created using the
empty method. But what
is the right VectorSpace? All solutions
of a Model belong to its solution_space,
so we write:
training_data = fom.solution_space.empty()
for mu in training_set:
training_data.append(fom.solve(mu))
Note that fom.solve returns a VectorArray containing a single vector.
This entire array (of one vector) is then appended to the training_data array.
pyMOR has no notion of single vectors, we only speak of VectorArrays.
What exactly is a VectorSpace? A VectorSpace in pyMOR holds all
information necessary to build VectorArrays containing vector objects
of a certain type. In our case we have
fom.solution_space
NumpyVectorSpace(20201, id='STATE')
which means that the created VectorArrays will internally hold
NumPy arrays for data storage. The number is the dimension of the
vector. We have here a NumpyVectorSpace because pyMOR’s builtin
discretizations are built around the NumPy/SciPy stack. If fom would
represent a Model living in an external PDE solver, we would have
a different type of VectorSpace which, for instance, might hold a
reference to a discrete functions space object inside the PDE solver
instead of the dimension.
After appending all solutions vectors to training_data, we can verify that
training_data now really contains 25 vectors:
len(training_data)
25
Note that appending one VectorArray V to another array U
will append copies of the vectors in V to U. So
modifying U will not affect V.
Let’s look at the solution snapshots we have just computed using
the visualize method of fom.
A VectorArray containing multiple vectors is visualized as a
time series:
fom.visualize(training_data)
A trivial reduced basis¶
Given some snapshot data, the easiest option to get a reduced basis is to just use the snapshot vectors as the basis:
trivial_basis = training_data.copy()
Note that assignment in Python never copies data! Thus, if we had written
trivial_basis = training_data and modified trivial_basis, training_data would
change as well, since trivial_basis and training_data would refer to the same
VectorArray object. So whenever you want to use one VectorArray
somewhere else and you are unsure whether some code might change the
array, you should always create a copy. pyMOR uses copy-on-write semantics
for copies of VectorArrays, which means that generally calling
copy is cheap as it does
not duplicate any data in memory. Only when you modify one of the arrays
the data will be copied.
Now we want to know how good our reduced basis is. So we want to compute
where \(V_N\) denotes the span of our reduced basis, for all
\(\mu\) in some validation set of parameter values. Assuming that
we are in a Hilbert space, we can compute the infimum via orthogonal
projection onto \(V_N\): in that case, the projection will be the
best approximation in \(V_N\) and the norm of the difference between
\(u(\mu)\) and its orthogonal projection will be the best-approximation
error.
So let \(v_{proj}\) be the orthogonal projection of \(v\) onto the linear space spanned by the basis vectors \(u_i,\ i=1, \ldots, N\). By definition this means that \(v - v_{proj}\) is orthogonal to all \(u_i\):
Let \(\lambda_j\), \(j = 1, \ldots, N\) be the coefficients of \(v_{proj}\) with respect to this basis, i.e. \(\sum_{j=1}^N \lambda_j u_j = v_{proj}\). Then:
With \(G_{i,j} := (u_i, u_j)\), \(R := [(v, u_1), \ldots, (v, u_N)]^T\) and \(\Lambda := [\lambda_1, \ldots, \lambda_N]^T\), we obtain the linear equation system
which determines \(\lambda_i\) and, thus, \(v_{proj}\).
Let’s assemble and solve this equation system using pyMOR to determine
the best-approximation error in trivial_basis for some test vector
V which we take as another random solution of our Model:
U = fom.solve(parameter_space.sample_randomly())
The matrix \(G\) of all inner products between vectors in trivial_basis
is a so called Gramian matrix.
Consequently, every VectorArray has a gramian method, which computes precisely
this matrix:
G = trivial_basis.gramian()
The Gramian is computed w.r.t. the Euclidean inner product. For the
right-hand side \(R\), we need to compute all (Euclidean) inner
products between the vectors in trivial_basis and (the single vector in)
U. For that, we can use the inner
method:
R = trivial_basis.inner(U)
which will give us a \(25\times 1\) NumPy array of all inner products.
Now, we can use NumPy to solve the linear equation system:
lambdas = np.linalg.solve(G, R)
Finally, we need to form the linear combination
using the lincomb method
of trivial_basis. It expects row vectors of linear coefficients, but
solve returns column vectors, so we need to take the transpose:
U_proj = trivial_basis.lincomb(lambdas.T)
Let’s look at U, U_proj and the difference of both. VectorArrays of
the same length can simply be subtracted, yielding a new array of the
differences:
# for some reason V_proj does not carry over from the previous cell
U_proj = trivial_basis.lincomb(lambdas.T)
fom.visualize((U, U_proj, U - U_proj),
legend=('U', 'U_proj', 'best-approximation err'),
separate_colorbars=True)
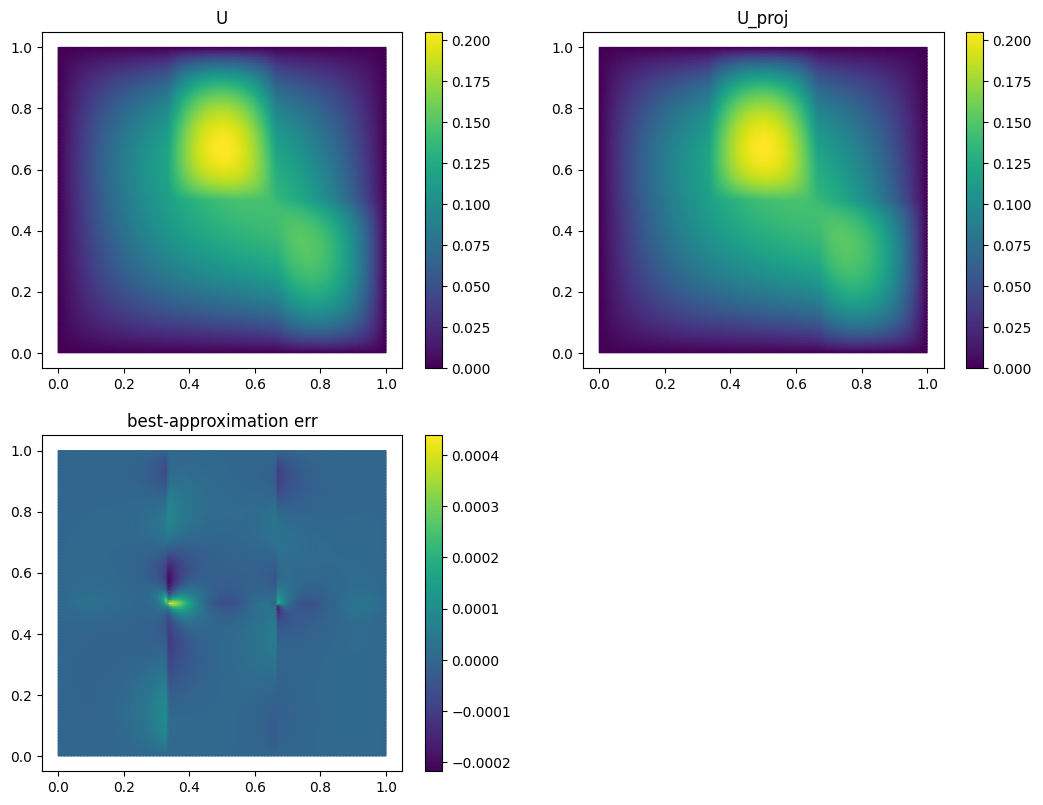
As you can see, we already have a quite good approximation of U with
only 25 basis vectors.
Now, the Euclidean norm will just work fine in many cases. However, when the full-order model comes from a PDE, it will be usually not the norm we are interested in, and you may get poor results for problems with strongly anisotropic meshes.
For our diffusion problem with homogeneous Dirichlet boundaries,
the Sobolev semi-norm (of order one) is a natural choice. Among other useful products,
discretize_stationary_cg already
assembled a corresponding inner product Operator for us, which is available
as
fom.h1_0_semi_product
NumpyMatrixOperator(<20201x20201 sparse, 98609 nnz>, source_id='STATE', range_id='STATE', name='h1_0_semi')
Note
The 0 in h1_0_semi_product refers to the fact that rows and columns of
Dirichlet boundary DOFs have been cleared in the matrix of the Operator to
make it invertible. This is important for being able to compute Riesz
representatives w.r.t. this inner product (required for a posteriori
estimation of the ROM error). If you want to compute the H1 semi-norm of a
function that does not vanish at the Dirichlet boundary, use
fom.h1_semi_product.
To use fom.h1_0_semi_product as an inner product Operator for computing the
projection error, we can simply pass it as the optional product argument to
gramian and
inner:
G = trivial_basis[:10].gramian(product=fom.h1_0_semi_product)
R = trivial_basis[:10].inner(U, product=fom.h1_0_semi_product)
lambdas = np.linalg.solve(G, R)
U_h1_proj = trivial_basis[:10].lincomb(lambdas.T)
fom.visualize((U, U_h1_proj, U - U_h1_proj), separate_colorbars=True)
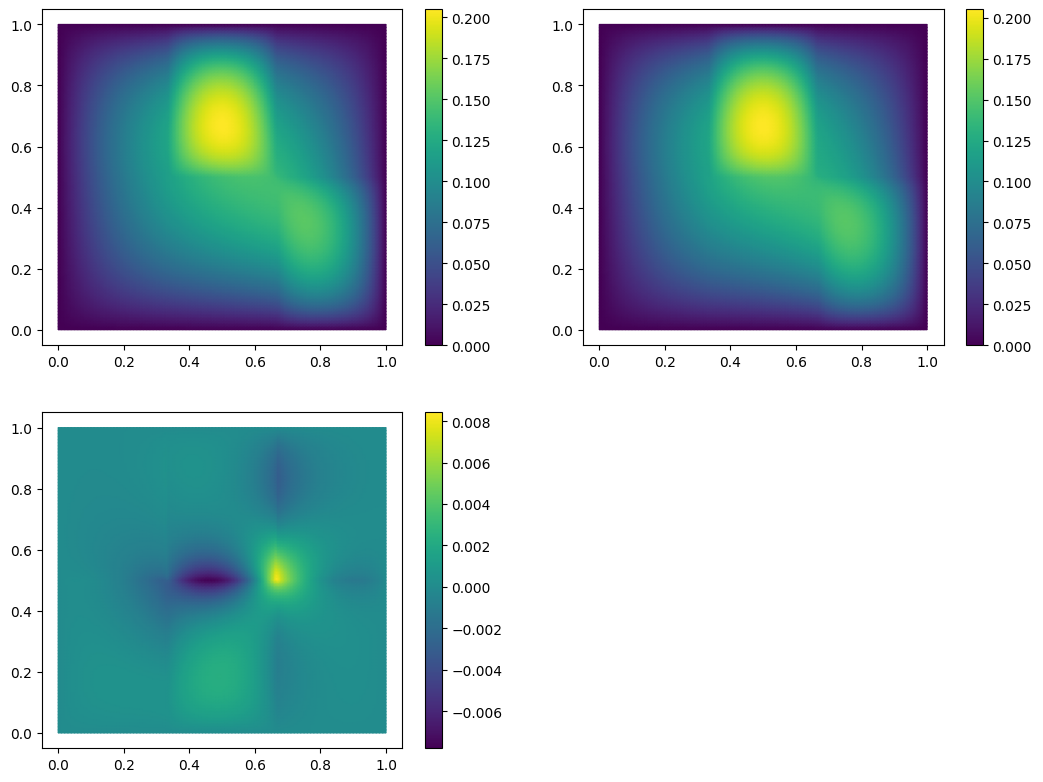
As you might have guessed, we have additionally opted here to only use the
span of the first 10 basis vectors of trivial_basis. Like NumPy arrays,
VectorArrays can be sliced and indexed. The result is always a
view onto the
original data. If the view object is modified, the original array is modified
as well.
Next we will assess the approximation error a bit more thoroughly, by checking how well the training data is approximated for varying basis sizes.
To optimize the computation of the projection matrix and the right-hand side for varying basis sizes, we first compute these for the full basis and then extract appropriate sub-matrices:
def compute_proj_errors(basis, V, product):
G = basis.gramian(product=product)
R = basis.inner(V, product=product)
errors = []
for N in range(len(basis) + 1):
if N > 0:
v = np.linalg.solve(G[:N, :N], R[:N, :])
else:
v = np.zeros((0, len(V)))
V_proj = basis[:N].lincomb(v.T)
errors.append(np.max((V - V_proj).norm(product=product)))
return errors
trivial_errors = compute_proj_errors(trivial_basis, training_data, fom.h1_0_semi_product)
Here we have used the fact that we can form multiple linear combinations at once by passing
multiple rows of linear coefficients to
lincomb. The
norm method returns a
NumPy array of the norms of all vectors in the array with respect to
the given inner product Operator. When no norm is specified, the Euclidean
norms of the vectors are computed.
Let’s plot the projection errors:
from matplotlib import pyplot as plt
plt.figure()
plt.semilogy(trivial_errors)
plt.ylim(1e-5, 1e1)
plt.show()
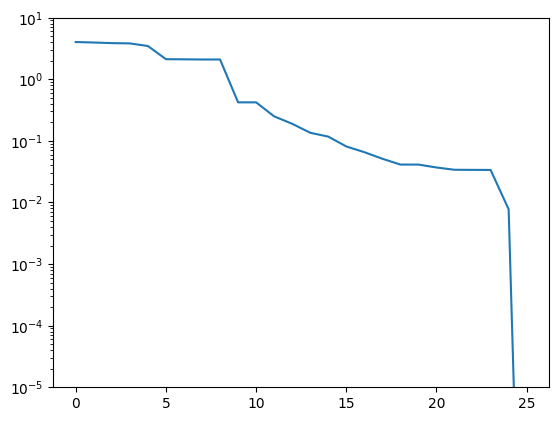
Good! We see an exponential decay of the error with growing basis size. The error drops to zero at the end as the basis contains all vectors it needs to approximate.
We can do better, however. If we want to use a smaller basis than we have snapshots available, just picking the first of these obviously won’t be optimal.
Strong greedy algorithm¶
The strong greedy algorithm iteratively builds reduced spaces \(V_N\) with a small worst-case best approximation error on a training set of solution snapshots by adding, in each iteration, the currently worst-approximated snapshot vector to the basis of \(V_N\).
We can easily implement it as follows:
def strong_greedy(U, product, N):
basis = U.space.empty()
for n in range(N):
# compute projection errors
G = basis.gramian(product)
R = basis.inner(U, product=product)
lambdas = np.linalg.solve(G, R)
U_proj = basis.lincomb(lambdas.T)
errors = (U - U_proj).norm(product)
# extend basis
basis.append(U[np.argmax(errors)])
return basis
Obviously, this algorithm is not optimized as we keep computing inner products we already know, but it will suffice for our purposes. Let’s compute a reduced basis using the strong greedy algorithm:
greedy_basis = strong_greedy(training_data, fom.h1_0_product, 25)
We compute the approximation errors for the training data as before:
greedy_errors = compute_proj_errors(greedy_basis, training_data, fom.h1_0_semi_product)
plt.figure()
plt.semilogy(trivial_errors, label='trivial')
plt.semilogy(greedy_errors, label='greedy')
plt.ylim(1e-5, 1e1)
plt.legend()
plt.show()
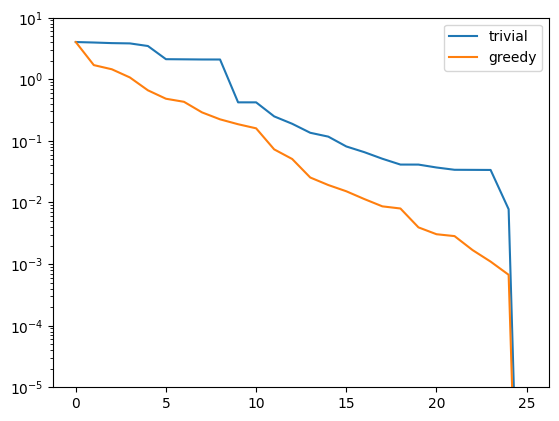
Indeed, the strong greedy algorithm constructs better bases than the trivial basis construction algorithm. For compact training sets contained in a Hilbert space, it can actually be shown that the greedy algorithm constructs quasi-optimal spaces in the sense that polynomial or exponential decay of the N-widths \(d_N\) yields similar rates for the worst-case best-approximation errors of the constructed \(V_N\).
Orthonormalization required¶
There is one technical problem with both algorithms however: the condition numbers of the Gramians used to compute the projection onto \(V_N\) explode:
G_trivial = trivial_basis.gramian(fom.h1_0_semi_product)
G_greedy = greedy_basis.gramian(fom.h1_0_semi_product)
trivial_conds, greedy_conds = [], []
for N in range(1, len(training_data)):
trivial_conds.append(np.linalg.cond(G_trivial[:N, :N]))
greedy_conds.append(np.linalg.cond(G_greedy[:N, :N]))
plt.figure()
plt.semilogy(range(1, len(training_data)), trivial_conds, label='trivial')
plt.semilogy(range(1, len(training_data)), greedy_conds, label='greedy')
plt.legend()
plt.show()
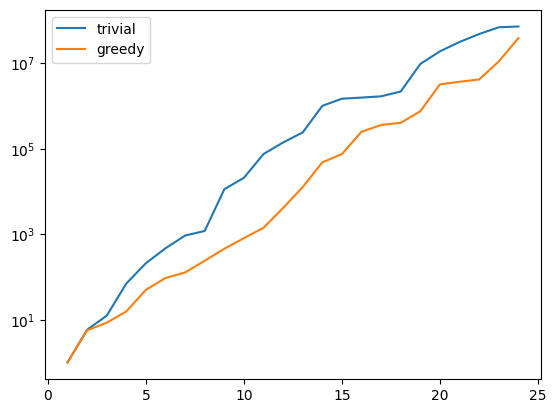
This is quite obvious as the snapshot data becomes more and more linear dependent the larger it grows.
If we would use the bases we just constructed to build a reduced-order model from them, we will quickly get bitten by the limited accuracy of floating-point numbers.
There is a simple remedy however: we orthonormalize our bases. The standard
algorithm in pyMOR to do so, is a modified
gram_schmidt procedure with
re-orthogonalization to improve numerical accuracy:
gram_schmidt(greedy_basis, product=fom.h1_0_semi_product, copy=False)
gram_schmidt(trivial_basis, product=fom.h1_0_semi_product, copy=False)
The copy=False argument tells the algorithm to orthonormalize
the given VectorArray in-place instead of returning a new array with
the orthonormalized vectors.
Since the vectors in greedy_basis and trivial_basis are now orthonormal,
their Gramians are identity matrices (up to numerics). Thus, their condition
numbers should be near 1:
G_trivial = trivial_basis.gramian(fom.h1_0_semi_product)
G_greedy = greedy_basis.gramian(fom.h1_0_semi_product)
print(f'trivial: {np.linalg.cond(G_trivial)}, '
f'greedy: {np.linalg.cond(G_greedy)}')
trivial: 1.0000000000000062, greedy: 1.000000000000004
Orthonormalizing the bases does not change their linear span, so best-approximation errors stay the same. Also, we can compute these errors now more easily by exploiting orthogonality:
def compute_proj_errors_orth_basis(basis, V, product):
errors = []
for N in range(len(basis) + 1):
v = V.inner(basis[:N], product=product)
V_proj = basis[:N].lincomb(v)
errors.append(np.max((V - V_proj).norm(product)))
return errors
trivial_errors = compute_proj_errors_orth_basis(trivial_basis, training_data, fom.h1_0_semi_product)
greedy_errors = compute_proj_errors_orth_basis(greedy_basis, training_data, fom.h1_0_semi_product)
plt.figure()
plt.semilogy(trivial_errors, label='trivial')
plt.semilogy(greedy_errors, label='greedy')
plt.ylim(1e-5, 1e1)
plt.legend()
plt.show()
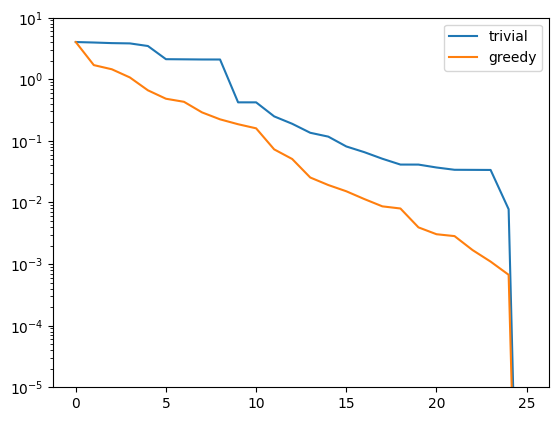
Proper Orthogonal Decomposition¶
Another popular method to create a reduced basis out of snapshot data is the so-called Proper Orthogonal Decomposition (POD) which can be seen as a non-centered version of Principal Component Analysis (PCA). First we build a snapshot matrix
where \(K\) denotes the total number of solution snapshots. Then we compute the SVD of \(A\)
where \(\Sigma\) is an \(r \times r\)-diagonal matrix, \(U\) is an \(n \times r\)-matrix
and \(V\) is an \(K \times r\)-matrix. Here \(n\) denotes the dimension of the
solution_space and \(r\) is the rank of \(A\).
The diagonal entries \(\sigma_i\) of \(\Sigma\) are the singular values of \(A\), which are
assumed to be monotonically decreasing. The pairwise orthogonal and normalized
columns of \(U\) and \(V\) are the left- resp. right-singular vectors of \(A\).
The \(i\)-th POD mode is than simply the \(i\)-th left-singular vector of \(A\),
i.e. the \(i\)-th column of \(U\). The larger the corresponding singular value is,
the more important is this vector for the approximation of the snapshot data. In fact, if we
let \(V_N\) be the span of the first \(N\) left-singular vectors of \(A\), then
the following error identity holds:
Thus, the linear spaces produced by the POD are actually optimal, albeit in a different
error measure: instead of looking at the worst-case best-approximation error over all
parameter values, we minimize the \(\ell^2\)-sum of all best-approximation errors.
So in the mean squared average, the POD spaces are optimal, but there might be parameter values
for which the best-approximation error is quite large.
So far we completely neglected that the snapshot vectors may lie in a Hilbert space
with some given inner product. To account for that, instead of the snapshot matrix
\(A\), we consider the linear mapping that sends the \(i\)-th canonical basis vector
\(e_k\) of \(\mathbb{R}^K\) to the vector \(u(\mu_k)\) in the
solution_space:
Also for this finite-rank (hence compact) operator there exists a SVD of the form
with orthonormal vectors \(u_i\) and \(v_i\) that generalizes the SVD of a matrix.
The POD in this more general form is implemented in pyMOR by the
pod method, which can be called as follows:
pod_basis, pod_singular_values = pod(training_data, product=fom.h1_0_semi_product, modes=25)
We said that the POD modes (left-singular vectors) are orthonormal with respect to the inner product on the target Hilbert-space. Let’s check that:
np.linalg.cond(pod_basis.gramian(fom.h1_0_semi_product))
1.0000000000000033
Now, let us compare how the POD performs against the greedy algorithm in the worst-case best-approximation error:
pod_errors = compute_proj_errors_orth_basis(pod_basis, training_data, fom.h1_0_semi_product)
plt.figure()
plt.semilogy(trivial_errors, label='trivial')
plt.semilogy(greedy_errors, label='greedy')
plt.semilogy(pod_errors, label='POD')
plt.ylim(1e-5, 1e1)
plt.legend()
plt.show()
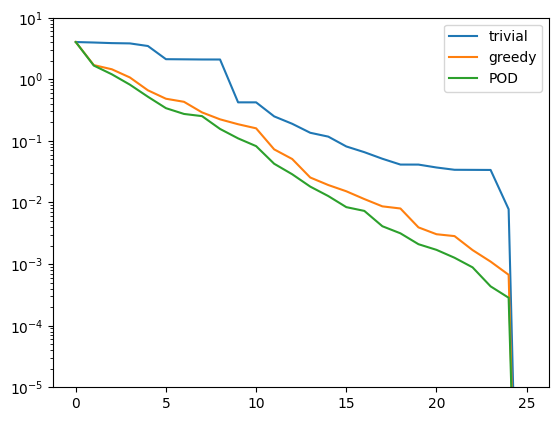
As it turns out, the POD spaces perform even slightly better than the greedy spaces. Why is that the case? Note that for finite training or validation sets, both considered error measures are equivalent. In particular:
Since POD spaces are optimal in the \(\ell^2\)-error, they miss the error of the optimal space in the Kolmogorov sense by at most a factor of \(\sqrt{K}\), which in our case is \(5\). On the other hand, the greedy algorithm also only produces quasi-optimal spaces. – For very large training sets with more complex parameter dependence, differences between both spaces may be more significant.
Finally, it is often insightful to look at the POD modes themselves:
fom.visualize(pod_basis)
As you can see, the first (more important) basis vectors account for the approximation of the solutions in the bulk of the subdomains, whereas the higher modes are responsible for approximating the solutions at the subdomain interfaces.
Weak greedy algorithm¶
Both POD and the strong greedy algorithm require the computation of all
solutions \(u(\mu)\)
for all parameter values \(\mu\) in the training_set. So it is
clear right from the start that we cannot afford very large training sets.
Otherwise we would not be interested in model order reduction
in the first place. This is a problem when the number of |parameters|
increases and/or the solution depends less uniformly on the |parameters|.
Reduced basis methods have a very elegant solution to this problem, which allows training sets that are orders of magnitude larger than the training sets affordable for POD: instead of computing the best-approximation error we only compute a surrogate
for it. Replacing the best-approximation error by this surrogate in the
strong greedy algorithm, we arrive at the
weak greedy
algorithm. If the surrogate \(\mathcal{E}(\mu)\) is an upper and lower bound
to the best-approximation error up to some fixed factor, it can still be shown that the
produced reduced spaces are quasi-optimal in the same sense as for the strong greedy
algorithm, although the involved constants might be worse, depending on the
efficiency of \(\mathcal{E}(\mu)\).
Now here comes the trick: to get a surrogate that can be quickly computed, we can use our current reduced-order model for it. More precisely, we choose \(\mathcal{E}(\mu)\) to be of the form
So to compute the surrogate for fixed parameter values \(\mu\), we first
solve the reduced-order model for the current
reduced basis for these parameter values and then compute an estimate for the
model order reduction error.
We won’t go into any further details in this tutorial, but for nice problem classes
(linear coercive problems with an affine dependence of the system matrix on the Parameters),
one can derive a posteriori error estimators for which the equivalence with the best-approximation
error can be shown and which can be computed efficiently, independently from the size
of the full-order model. Here we will only give a simple example how to use the
weak greedy algorithm for our problem at hand.
In order to do so, we need to be able to build a reduced-order
model with an appropriate error estimator. For the given (linear coercive) thermal block problem
we can use CoerciveRBReductor:
reductor = CoerciveRBReductor(
fom,
product=fom.h1_0_semi_product,
coercivity_estimator=ExpressionParameterFunctional('min(diffusion)', fom.parameters)
)
Here product specifies the inner product with respect to which we want to compute the
model order reduction error. With coercivity_estimator we need to specify
a function which estimates the coercivity constant of the system matrix with respect to
the given inner product. In our case, this is just the minimum of the diffusivities over
all subdomains.
Now we can call rb_greedy, which constructs for us the
surrogate \(\mathcal{E}(\mu)\) from fom and the reductor we just
constructed. It then passes this surrogate to the weak_greedy
method. Furthermore, we need to specify the number of basis vectors we want to compute
(we could also have specified an error tolerance) and the training set.
As the surrogate is cheap to evaluate, we choose here a training set of 1000 different
parameter values:
greedy_data = rb_greedy(fom, reductor, parameter_space.sample_randomly(1000),
max_extensions=25)
Take a look at the log output to see how the basis is built iteratively using the surrogate \(\mathcal{E}(\mu)\).
The returned greedy_data dictionary contains various information about the run
of the algorithm, including the final ROM. Here, however, we are interested in the
generated reduced basis, which is managed by the reductor:
weak_greedy_basis = reductor.bases['RB']
Let’s see, how the weak-greedy basis performs:
weak_greedy_errors = compute_proj_errors_orth_basis(weak_greedy_basis, training_data, fom.h1_0_semi_product)
plt.figure()
plt.semilogy(trivial_errors, label='trivial')
plt.semilogy(greedy_errors, label='greedy')
plt.semilogy(pod_errors, label='POD')
plt.semilogy(weak_greedy_errors, label='weak greedy')
plt.ylim(1e-7, 1e2)
plt.legend()
plt.show()
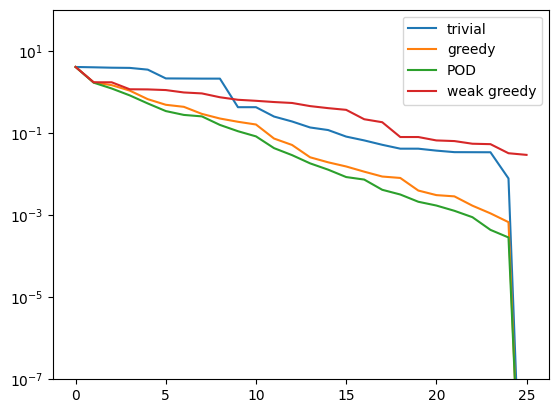
We see that the weak-greedy basis is worse than all the other bases! How can that be? Remember that the weak-greedy basis was trained for a new training data set of 1000 parameter values and not the original much smaller training data set. So what we actually see here is that the other bases are very good at approximating this small training data set, but likely do not generalize well to the entire solution manifold \(\mathcal{M}\).
To check this, we compute an additional validation data set of 100 new parameter values:
validation_set = parameter_space.sample_randomly(100)
validation_data = fom.solution_space.empty()
for mu in validation_set:
validation_data.append(fom.solve(mu))
Let’s see how the approximation error decays on the validation set:
trivial_errors = compute_proj_errors_orth_basis(trivial_basis, validation_data, fom.h1_0_semi_product)
greedy_errors = compute_proj_errors_orth_basis(greedy_basis, validation_data, fom.h1_0_semi_product)
pod_errors = compute_proj_errors_orth_basis(pod_basis, validation_data, fom.h1_0_semi_product)
weak_greedy_errors = compute_proj_errors_orth_basis(weak_greedy_basis, validation_data, fom.h1_0_semi_product)
plt.figure()
plt.semilogy(trivial_errors, label='trivial')
plt.semilogy(greedy_errors, label='greedy')
plt.semilogy(pod_errors, label='POD')
plt.semilogy(weak_greedy_errors, label='weak greedy')
plt.ylim(1e-2, 5e1)
plt.legend()
plt.show()
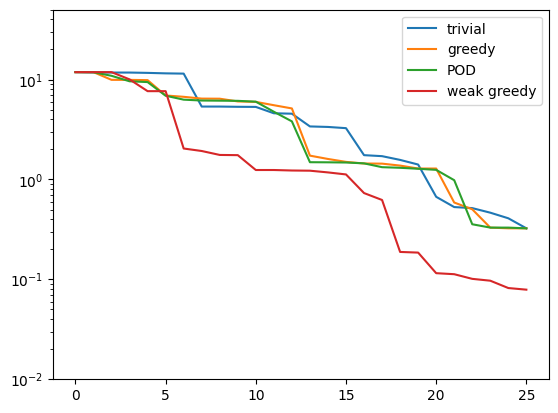
Indeed we see that the weak-greedy basis generalizes to the validation data much better than all the other bases.
Download the code:
tutorial_basis_generation.md
tutorial_basis_generation.ipynb